


 EN
ENAutomated Adverse Media Screening
We are at the cutting edge of machine learning classification, collating all adverse information and media you need into comprehensive, structured profiles.
Get Started NowKeywords in adverse media are simple, but they just don’t work very well.
Adverse media (AKA “negative news” or sometimes “special interest persons”) is a growing concern for financial institutions. The ability to pre-empt financial crime based on relevant information generated by thousands of publications, and hundreds of thousands of journalists and researchers around the world, is gaining acceptance as a necessary complement to existing compliance and risk management approaches. All major guiding bodies and regulators (FATF; FCA; FinCEN; Wolfsberg; etc.) recommend, and often require, negative news screening of customers and other third parties. Leading financial institutions typically surpass these guidelines based on their anticipation of regulator scrutiny, but also protection of their brand in a highly competitive market.
The challenge for these institutions is to improve their defenses against adverse media-related risks while ensuring that their businesses remain efficient, and their products competitive. Risk data providers have sought to address this challenge in various ways, with the current status quo leveraging adverse media keywords as their core technology. The problem is that keywords just don’t work when you need them to.
They create gaps in your defenses and result in huge inefficiencies. The original way that “adverse media” or “special interest person” profiles were created was via a manual research process. A large team of analysts would comb through the news and pick out anyone who posed some kind of significant AML/CFT risk. They would then put this information into their risk database, first checking to see if something already existed, and often erring on the side of caution when they couldn’t tell if someone was the same person as a profile they had previously created (by then creating a duplicate profile).
This would lead to a small, but relatively high-quality database – with just a couple of major problems:
Many databases are still created this way and are available from some very prominent, and publicly listed, data providers. But the gaps in their coverage are large, and they do not provide an adequate defense to firms truly looking to be aware of AML/CFT related adverse media risks that 3rd parties may pose to them.
This situation, and the rise of search engines, presented an opportunity to take a seemingly more advanced and scalable approach: keywords in adverse media.
One of the most common questions we get when talking to our current and prospective customers is “which keywords do you use?”. It’s an excellent question if a provider is using adverse media keywords to identify risky entities.
Keywords in adverse media are correctly presumed to work like this:
Leave aside the issue about whether or not this is the right John Smith, for the most part, it worked. Someone with the same name as your customer appeared in a sentence with a word related to an AML/CFT risk you care about.
But what if the result you got back was:
“Michael Jones has been charged for fraud, said district attorney John Smith.”
It “worked”, but clearly the John Smith here is not the perpetrator and the result is not relevant. In reality, the majority of results are going to be versions of this where most of the people in an article are either the victim, law enforcement, witnesses, journalists, etc.
And how about:
“John Smith behaved fraudulently, according to prosecutors.”
In this case, the risk word was “fraudulently”, but the search was for “fraud” – so instead of getting too much noise, you have potentially missed an important risk. Unless you also include some additional adverse media keywords like: fraud; frauds; defraud; defrauds; fraudulent; defrauded; fraudful; defrauding; fraudulently; etc.
But if you’re including specific derivatives of the word “fraud”, why stop there? What about: deceit; deceived; scam; scammer; scamming; hoax; fake; swindle; hustle; etc. The list is long with near-endless permutations. And not every word is equally helpful in identifying risk – so you need to make a call at some point about whether to include a word or not based on the trade-off between the risk of missing something important vs. the amount of noise you have to deal with.
Oh, and by the way, if you’re using Google, your searches are limited to 32 words.
Consider the sentence:
“John Smith killed it on Sunday. He shot at the goal seven times, scoring thrice. His victim, goalie Michael Jones, clearly had his pride injured.”
As a human, we read this and immediately understand it’s about sport, despite the fact that it contains the words “killed”, “shot”, “victim”, “injured”. This is a simplistic example, but the problem is common across almost all keywords – they have different meanings in different contexts, and end up being a very blunt instrument. Think about “launder”, “dumping”, “charged”, or even “arrest”.
Here’s something different:
“John Smith, 47, was implicated in a case where dozens of investors, including Patience Chiwasa, lost significant portions of their retirement savings.”
What do you notice? Yes – there are no adverse media keywords at all in this sentence. “Implicated” is perhaps the strongest, but it’s used so commonly in other contexts that it would not be very predictive. But despite there being no risk keywords, as humans, we are easily able to identify that there is some risk associated with John Smith here – and we’d want to know about it, although we never would if we relied on keywords.
Finally, consider:
“John Smith fue declarado culpable de fraude.”
It’s a Spanish version of our first example (“John Smith was found guilty of fraud.”). Think about the basic problems in English, now multiply that by however many other languages you care about, and the additional language-specific nuances you would need to take into account.
Let’s, unrealistically, assume that the results returned from using keywords are good (ignoring all the problems above). We have a list of articles about adverse people called John Smith. Now what?
You need to go through all these results and understand whether or not they relate to your John Smith. Even if they do (and are not one of 100’s of other potential adverse John Smiths, or John Smith Inc.’s), you need to ensure that you’ve looked at the most relevant media and have a complete view of the entities – in many ways, the real work begins here.
Revisiting the question “what adverse media keywords do you use?”, the answer can be simple. But the complications behind the answer are vast. Really, the question itself is not the right one – it should be “how are you finding all the risk relevant to my business, and ensuring noise is kept to a minimum?”
In some ways, the problems with keywords in adverse media can be remedied by the first manual analyst approach. But, only on a small scale. What if there was a way to have orders of magnitude more of these analysts, who could work 24 hours a day, make consistent and unbiased decisions, read media in dozens of different languages, and be upskilled constantly and instantly?
Fortunately, there is a way to do this. Since 2012 the field of machine learning has exploded due to the availability of processing power, and several new techniques. The technology’s intersection with natural language processing (NLP) has been similarly eruptive – think of how quickly Siri, Alexa, Google Translate and other tools have arrived and become so competent.
At ComplyAdvantage we have been using this screening technology to produce high quality and broad AML/CFT data since we were founded 6 years ago. In particular, the challenge of building an adverse media database is very well suited to deep learning and NLP. It allows us to take a leap beyond keywords, and understand the true context within the written language.
Let’s take another look at some of the previous examples, but see what our machine learning systems sees. The below screenshots are from an internal diagnostic tool we use in development called the “Mention Checker” – it shows us what the system read and understood, but it is a few steps before we consolidate information and identifiers into an entity profile used by our customers.

This one is almost too easy, a simple declaration of the entity and the crime they committed with no other information.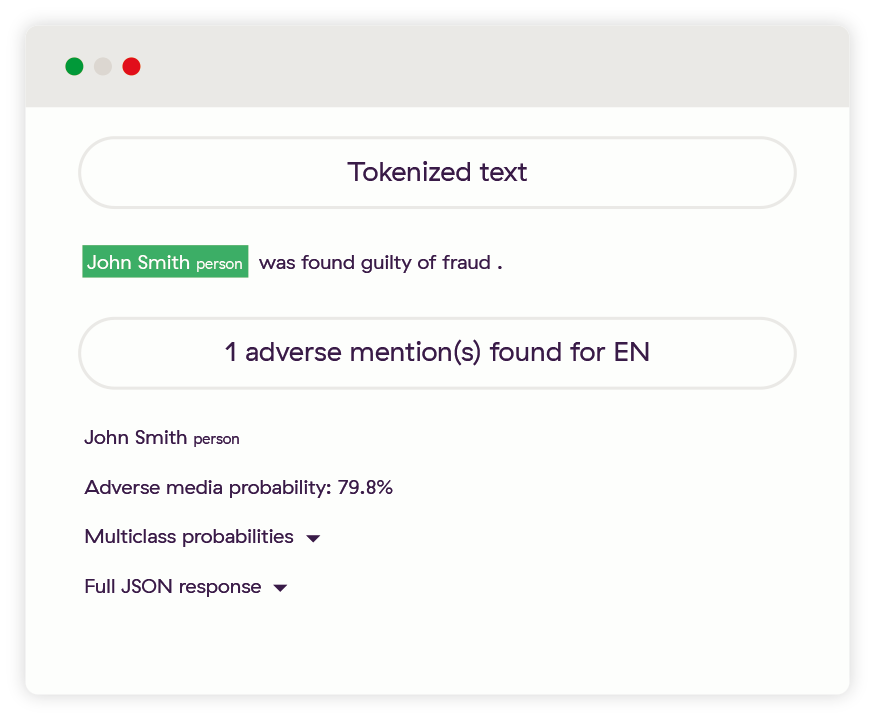
Here the John Smith entity was correctly found not to be adverse, while the Michael Jones entity clearly was.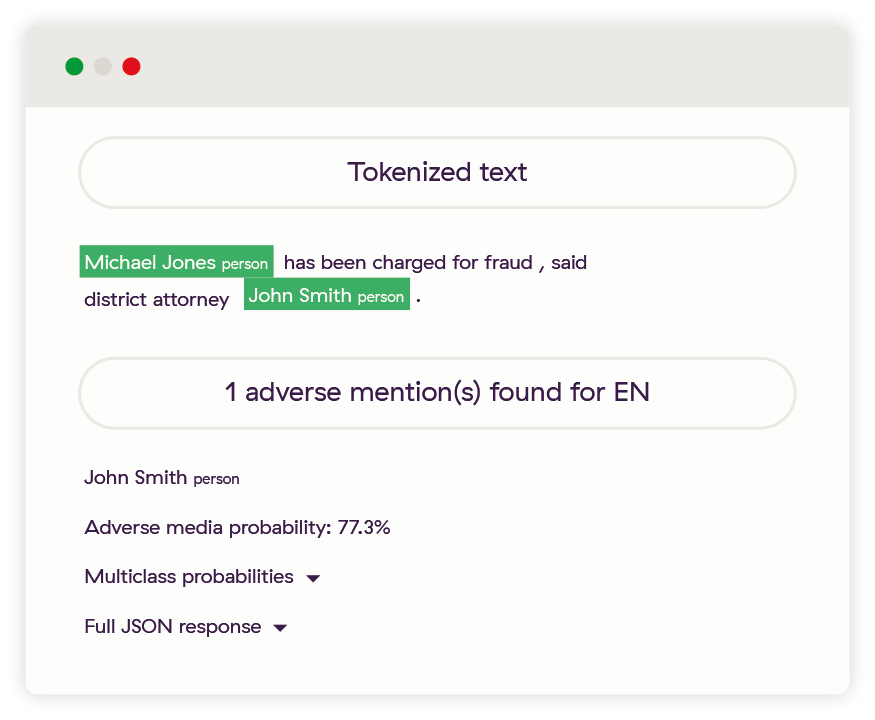
Here, the system found that John Smith was adverse, despite a key risk word being one of many forms of the root word “fraud.”
Despite these two sentences being full of risk words, neither of the entities was found to be adverse.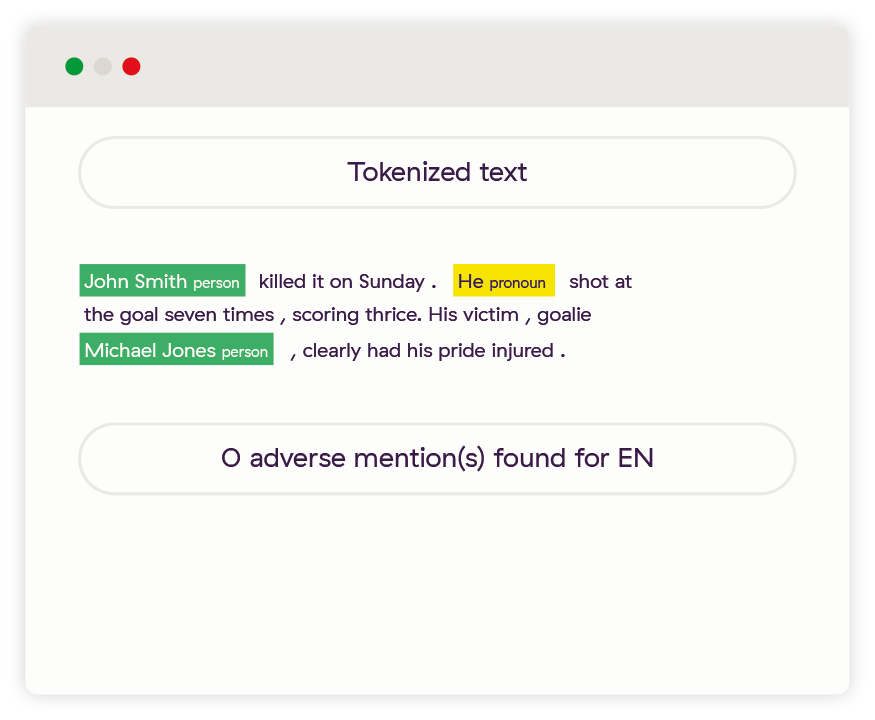
This example shows the true power of a deep learning system like ours. Not only is John Smith found to be adverse from this piece of media, we have also easily identified Patience Chiwasa (a person with a traditionally difficult to parse name) and understood that she’s not adverse. Additionally, we have identified an age for the John Smith entity which we use to calculate the year of birth – this forms part of the profile we would create allowing users to easily filter out irrelevant information based on what they know about their own customers.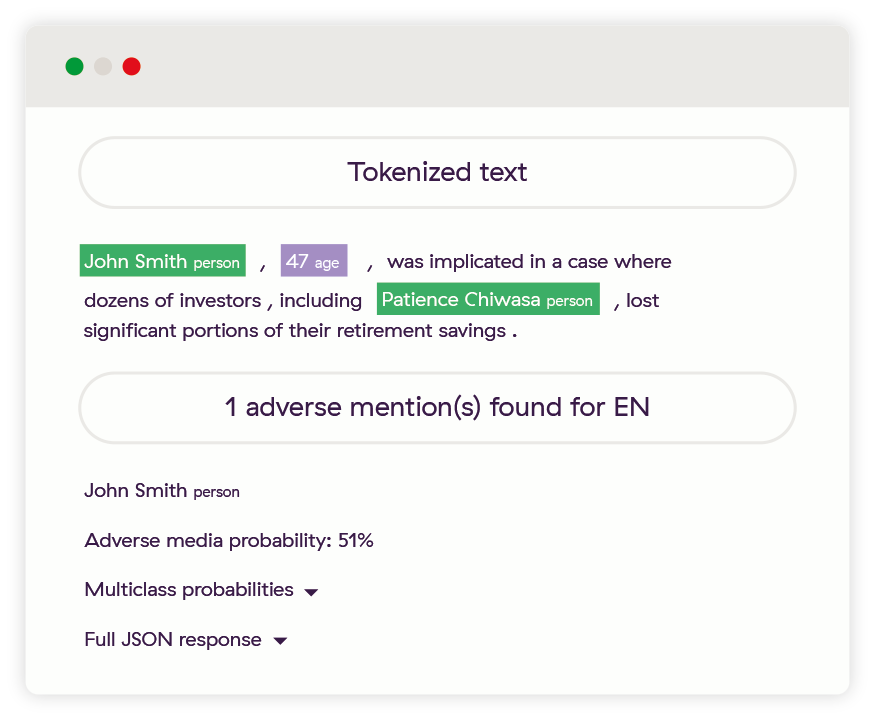
In this final example, John Smith is easily identified as being adverse in Spanish. As he would be in Portuguese, French, German, Italian, Dutch, Russian, Arabic, Chinese, or Japanese too.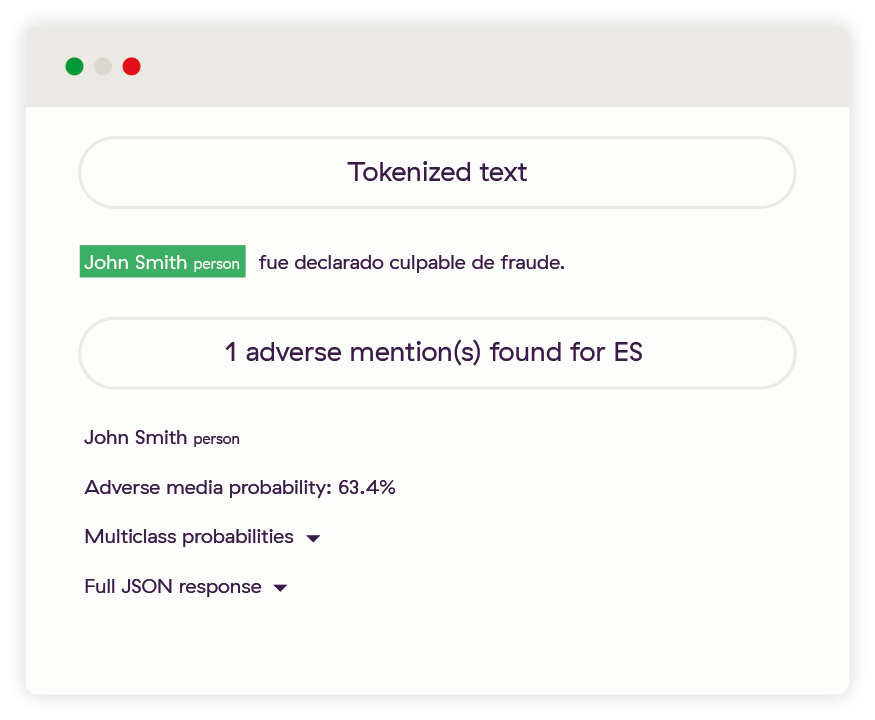
The intricate details of how we do this would take more than a few more pages to explain, but there are some core components that are important with regard to this different approach to keywords in adverse media.
This is a slide we use internally to convey how our system works – it’s dense with several concepts, but bear with us!
At the top, you see an example sentence. Our production system reviews up to a billion of these every day. The sentence gets broken down into component parts:

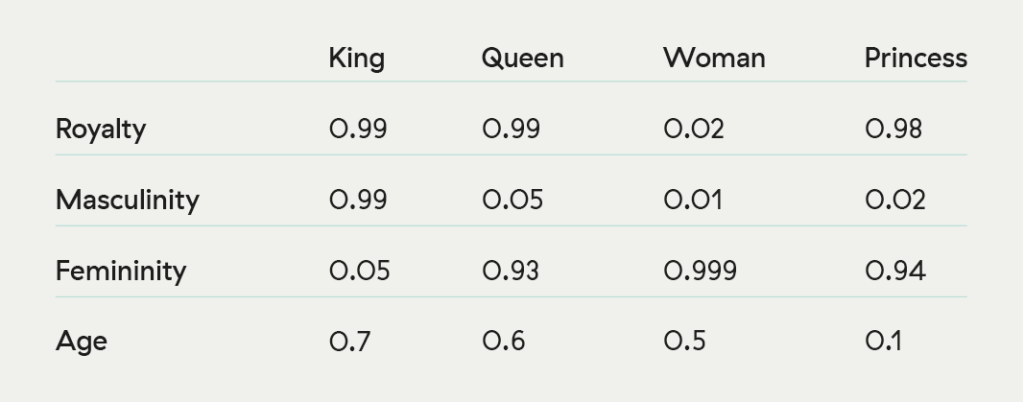
Next, we will convert all adverse media keywords into a form that a machine understands and is agnostic across languages. The image below is a simplified example of what is happening. Each word gets converted into some vector (column of numbers) that defines it according to some set of properties – here you can see only “King” scores highly on “masculinity”, while only “woman” scores low on “royalty”. The list of attributes is very very long, and in reality, not defined as clearly as this, but this is a general concept.
Finally, the keywords all pass through a deep neural network. The power of a neural network is that it is able to analyze every word in relation to every other word and take order into account. This enables it to:
This final point is crucial – by understanding the context, we can do more than say whether something is merely adverse or not. We can say what type of adverse media something is, which allows our customers to far more precisely manage their risk.
To do deep learning well, you need a few essential ingredients. Of course, you need some smart engineers, and you need an understanding of the problem. But something often overlooked is good quality examples to train models on. A machine learning system needs 100s of thousands to millions of examples in order to perform at the right level.
We have invested heavily in our training data, working with leading providers in the space, and constantly upgrading our models over the years. The quality and size of our keywords in adverse media training data is unparalleled, and constantly improving based on customer feedback.
Keywords were an intermediate step in the quest to scale the use of analysts and researchers manually looking for risk data. However, it creates many more challenges than it adequately solves.
A machine learning approach addresses the problems created by both the researcher and the keyword methods. It correctly identifies adverse media (of the correct person / organization) based on an understanding of the context, and not simply the presence of adverse media keywords. It can do this billions of times a day and is never limited to just a few publications.
Our machine learning is core to how we create the most powerful adverse media database in the world. We’ve only scratched the surface in terms of the potential this technology brings to financial crime fighting.
We are at the cutting edge of machine learning classification, collating all adverse information and media you need into comprehensive, structured profiles.
Get Started NowDisclaimer: This is for general information only. The information presented does not constitute legal advice. ComplyAdvantage accepts no responsibility for any information contained herein and disclaims and excludes any liability in respect of the contents or for action taken based on this information.
Copyright © 2024 IVXS UK Limited (trading as ComplyAdvantage).
