


 FR
FR EN
ENDemandez une démonstration
Découvrez comment plus de 1000 entreprises procèdent à un filtrage par rapport à la seule base de données de risques en temps réel au monde qui répertorie les personnes et les entreprises.
Demandez une démoLe filtrage de la couverture médiatique négative est devenu essentiel pour identifier les risques potentiels liés aux clients à l’heure où les établissements s’efforcent de protéger leurs actifs, leur réputation ainsi que les différents acteurs avec qui ils traitent. Si l’importance du filtrage des informations négatives est largement reconnue, déployer un processus de filtrage efficace et exhaustif reste complexe pour de nombreux établissements. L’un des principaux obstacles auxquels les établissements sont confrontés est un filtrage imparfait qui permet à des informations critiques de passer à travers les mailles du filet et d’exposer les établissements à d’éventuelles violations.
Le webinaire réunissant des experts du Groupe d’action financière (GAFI) et du cabinet d’études et de conseil de premier ordre Celent, a porté sur la contribution de la technologie pour combler les lacunes du processus de filtrage de la couverture médiatique négative. Le présent article s’appuie sur ces discussions pour voir comment l’apprentissage machine (ML) peut aider les établissements financiers à atténuer les défis du moment et réduire les risques liés au filtrage des informations médiatiques négatives.
En matière de filtrage d’informations négatives, le principal défi auquel les analystes sont confrontés est de passer au crible de gigantesques volumes de données pour identifier les informations pertinentes. L’un des principaux problèmes est la prévalence de données non pertinentes ou parasites. Ainsi, une recherche sur « Tiffany Palmer » sur Google génère plus de 70 000 résultats, même en y associant des mots-clés spécifiques tels que fraude ou blanchiment d’argent. Il peut donc s’avérer compliqué de trouver des informations pertinentes. Pour les personnes portant des noms courants tels que Pascal ou Alain Dupont, le nombre de résultats de recherche peut atteindre les 30 millions, ce qui rend très difficile la recherche de la bonne information.
Lorsque les analystes ne parviennent pas à affiner leur recherche, des difficultés peuvent survenir. En effet, même s’ils disposent de certaines informations sur leur client, dont sa date de naissance ou son lieu de résidence, il n’est pas toujours pratique d’utiliser des outils comme Google pour affiner les recherches. Nombreux sont ceux les analystes qui essaient de lire toutes les pages qui s’affichent, mais cette solution n’est ni efficace ni rapide. En effet, il reste difficile de distinguer les informations pertinentes de celles qui ne le sont pas et il peut être compliqué de savoir si deux personnes portant le même nom sont la même personne ou pas.
Autre défi, le suivi dans la durée des informations sur les risques que pose un client. Rien n’est moins pratique que de rechercher dans des millions de résultats après chaque mise à jour. Pour résoudre ce problème, certains établissements engagent de nombreux analystes qui lisent les articles et utilisent des règles de base pour filtrer les données non pertinentes. Cette approche reste toutefois limitée car soit elle restreint le volume d’informations que chaque analyste peut examiner, soit elle nécessite un plus grand nombre d’analystes pour traiter l’énorme quantité de données à consulter.
Certains établissements choisissent d’ignorer le problème tandis que d’autres se contentent de vérifier la couverture médiatique négative pour un groupe restreint de clients à haut risque. Malheureusement, procéder ainsi ne permet pas de traiter efficacement les risques éventuels. En effet, les personnes impliquées dans des délits financiers ne sont pas toujours identifiables en tant que clients à haut risque.
Les informations provenant de différentes sources, y compris de fausses nouvelles, de contenu satirique ou de sites Web extrémistes, il devient difficile d’évaluer la qualité et la crédibilité des données. Une vérification minutieuse de chaque source s’impose donc, ce qui complique encore le processus.
Il n’est pas conseillé de se fier uniquement à des sources bien connues telles que les journaux nationaux car cette approche peut faire passer à côté d’individus et de risques qui ne sont pas considérés comme importants à l’échelle nationale. La priorité étant d’identifier les risques avant qu’ils ne soient largement connus, il est donc nécessaire de s’appuyer sur une solution globale et efficace pour relever les défis du filtrage de la couverture médiatique négative.
L’apprentissage automatisée (ou ML) fournit des ressources d’automatisation pour surveiller en continu d’énormes volumes de médias sans se limiter à un ensemble spécifique. Les établissements financiers sont ainsi informés des risques susceptibles de les affecter. D’autres caractéristiques du ML permettent d’atténuer les défis classiques énumérés ci-dessus :
Tout d’abord, l’accès à une infrastructure de pointe s’est considérablement amélioré et permet désormais aux petits établissements d’accéder à des ressources auparavant réservées aux entités d’envergure. Les fournisseurs de services Cloud mettent à disposition du matériel facilement disponible et économique pour exécuter des tâches telles que l’extraction et le traitement de données, ce qui met tous les établissements sur un pied d’égalité.
Ensuite, les progrès remarquables réalisés dans le domaine de l’apprentissage automatique, en particulier au niveau du matériel et de l’infrastructure, ont joué un rôle crucial dans le développement ML. Les puces en silicium conçues pour l’apprentissage automatique sont désormais plus puissantes et plus accessibles. Ceci a permis aux établissements d’exploiter tout le potentiel des modèles de ML sans investir massivement dans des technologies et des serveurs coûteux. Qui plus est, la disponibilité des services Cloud leur permet d’opérer dans les régions où ils ont choisi de s’implanter tout en respectant les exigences et contraintes locales ou régionales en matière de données et de réglementation.
En outre, les progrès des techniques de ML, illustrés par les avancées dans le domaine du traitement du langage naturel, ont révolutionné le secteur. En effet, ce qui était autrefois considéré comme irréalisable est devenu réalité, le traitement du langage naturel se révélant un outil puissant pour lutter contre la criminalité financière et identifier les événements indésirables avec une précision remarquable.
L’afflux de données du monde réel a stimulé la croissance du ML, le rendant plus pertinent et utilisable pour résoudre des problèmes de taille. Le secteur compte aujourd’hui près d’un million de personnes qui se consacrent au marquage manuel et à l’annotation des données d’entraînement d’un modèle de ML, ce qui rend cette précieuse ressource accessible via différents mécanismes.
Malgré les défis bien connus du filtrage de la couverture médiatique négative et la sensibilisation à ces avancées technologiques, l’adoption efficace et intégrée de ces solutions reste limitée. Différents facteurs peuvent expliquer pourquoi les différents établissements hésitent encore à profiter des avantages offerts par ces technologies.
Des tentatives ont donc été faites pour résoudre le problème du filtrage des actualités négatives au moyen de différentes approches.
Comme indiqué plus haut, la première approche consiste à employer des analystes humains pour examiner les actualités et créer manuellement des profils consultables. Cette méthode est cependant conditionnée par le nombre d’analystes embauchés, ce qui restreint la portée de la couverture médiatique. En outre, des défis comme les disparités linguistiques et le manque de cohérence persistent.
La deuxième approche adoptée par les établissements financiers est une méthode fondée sur des mots-clés. Bien que plus dimensionnable et automatisée, elle présente des inconvénients, notamment une plus grande propension aux faux positifs. L’utilisation de mots-clés tels que « tirer », « tué » ou « terroriser » peut générer des résultats avec des contextes différents, ce qui ne permet pas aux sociétés de services financiers ou au département Conformité d’un établissement d’obtenir facilement des informations pertinentes. A contrario, en l’absence de mots-clés spécifiques, cette approche peut aussi ne pas parvenir à capturer des informations essentielles dans un article.
Compte tenu des limites des deux approches susmentionnées, les raisons pour lesquelles certains établissements hésitent encore à adopter une approche fondée sur le ML pour filtrer la couverture médiatique négative sont notamment :
ComplyAdvantage a développé une approche innovante pour son processus de filtrage de la couverture médiatique négative. Basé sur une API, le système comprend deux éléments principaux. Tout d’abord, une barre de recherche dans laquelle les clients peuvent saisir le nom d’une personne et des informations d’identification pertinentes dont le pays ou la date de naissance. Le système traite ensuite ces données pour identifier les profils de risque pouvant correspondre aux critères de recherche du client, ce qui facilite le processus d’entrée en relation d’affaires.
La deuxième phase du processus porte sur la collecte d’informations auprès de différentes sources disponibles sur Internet. ComplyAdvantage utilise la technologie de ML pour analyser et catégoriser ces données non structurées, ce qui permet de créer des profils pour des individus et des entreprises uniques qui pourront être consultés ultérieurement dans le cadre du filtrage de la couverture médiatique négative.
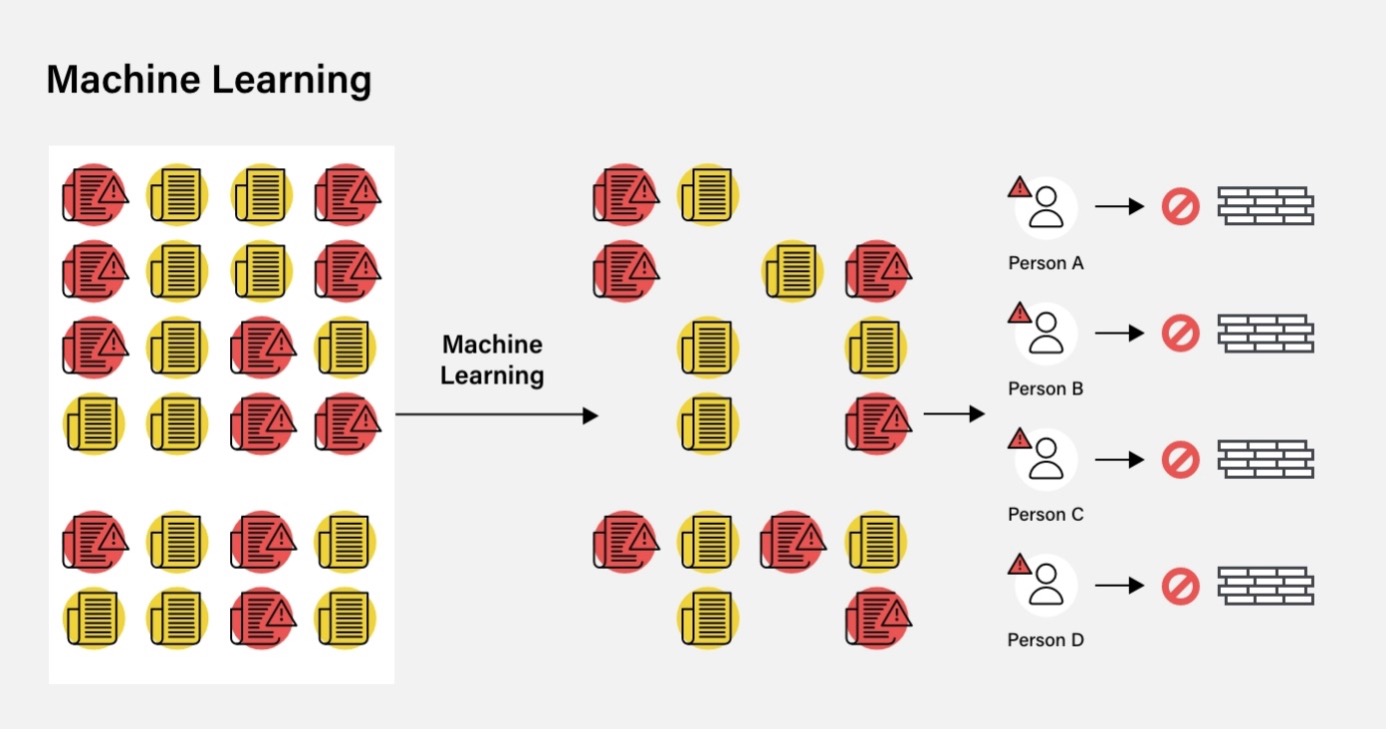
ComplyAdvantage veille à ce que sa base de données soit constamment mise à jour en temps réel, ce qui permet de disposer d’informations actualisées pour lancer des recherches sur des clients existants et les suivre en continu. Les algorithmes de ML lisent les informations médiatiques, identifient les personnes et les entreprises concernées, créent différentes catégories de médias défavorables et consolident ces données dans des profils complets.
Cette approche fondée sur le ML offre plusieurs avantages en termes de conformité :
Compte tenu des avantages qu’offre l’apprentissage automatique, il est légitime de se demander pourquoi s’appuyer dès maintenant sur cette technologie pour résoudre les problèmes liés à la couverture médiatique négative.
Deux facteurs clés justifient cette urgence.
La convergence de ces facteurs rappelle l’ampleur du problème à résoudre. Néanmoins, les progrès technologiques permettent désormais de relever ces défis efficacement.
Découvrez comment plus de 1000 entreprises procèdent à un filtrage par rapport à la seule base de données de risques en temps réel au monde qui répertorie les personnes et les entreprises.
Demandez une démoPublié initialement 18 octobre 2023, mis à jour 18 octobre 2023
Avertissement : Ce document est destiné à des informations générales uniquement. Les informations présentées ne constituent pas un avis juridique. ComplyAdvantage n'accepte aucune responsabilité pour les informations contenues dans le présent document et décline et exclut toute responsabilité quant au contenu ou aux mesures prises sur la base de ces informations.
Copyright © 2024 IVXS UK Limited (commercialisant sous le nom de ComplyAdvantage)
